예를 들어 사용자가 HDD(Non-Volatile Memory)와 같은 저장장치에 있는 프로그램을 실행하게 되면
프로그램이 프로세스 상태로 메모리에 적재되어 실행되며, 모든 프로세스는 부모 프로세스, 자식 프로세스로 분류되게 된다.
리눅스에서는 init(~CentOS6), systemd(CentOS7~)와 같은 시스템 최초의 프로세스로 "시스템 초기화 프로세스"라고 불린다.
프로세스 상태 조회에 자주 사용되는 명령어 'ps'를 알아보자
■ 명령어 'ps'의 활용방식
아무런 옵션 없이 사용하게 되면 현재 사용자의 화면에 표기되는 프로세스에 관해서만 보임
▼ 주로 사용되는 옵션은 코드블럭을 참조
ps -f '''현재 실행되는 프로세스에 관해 자세히 출력'''
ps -a '''다른 사용자의 프로세스까지 함께 출력'''
ps -u '''해당 프로세스를 실행중인 사용자의 정보와 시간을 함께 출력'''
ps -x '''백그라운드 프로세스까지 출력'''
ps -aux '''리소스 사용률을 기반으로 프로세스의 상태를 확인'''
ps -ef '''실행중인 모든 프로세스의 상속관계를 기반으로 자세히 확인'''
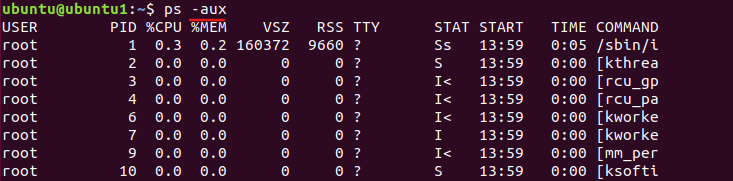
명령어 'ps'에 옵션 '-aux'를 함께 사용
해당 출력내용의 상단부를 보면 필드별로 나누어진 모습을 볼 수 있는데,
- USER : 프로세스의 소유자
- PID(Process ID) : 프로세스의 번호
- %CPU : 프로세스가 CPU를 차지하는 비율
- %MEM : 프로세스가 메모리를 점유하는 비율
- VSZ(Virtual Set siZe) : 프로세스에 할당된 가상 메모리의 크기
- RSS(Resident Set Size) : 프로세스가 현재 사용하는 메모리 비율
- STAT : 프로세스의 상태
- START : 프로세스가 시작된 시간
- TIME : 프로세스의 총 실행 시간
- COMMAND : 프로세스를 실행시킨 명령
▶ 프로세스의 상태(status)를 알려주는 필드 'STAT' 값의 의미
- R(Run/Runable) : 프로세스가 실행중 또는 실행가능
- D(in Disk wait) : 입출력이 완료될 때까지 깨울 수 없는 상태(수면상태)
-S(Sleeping) : 대기 중, 수면상태(전환 가능한 상태)
-T(sTopped) : 외부 시그널로 인해 일시 정지된 상태
-Z(Zombie) : 부모 프로세스가 종료 시그널을 정상적으로 수신 못해, 수습되지 않고 남은 상태
- < : 우선순위가 높은 프로세스
- N : 우선순위가 낮은 프로세스
- I(Idle) : 유휴(쉬고있는) 프로세스
명령어 'ps'에 옵션 '-ef'를 함께 사용
'-aux' 옵션을 사용했을 때와는 필드에 중복되지 않는 새로운 정보가 표기되는 것을 확인할 수 있다.
여기서 '도와주는' 이라고 표현을 했는데, 그 이유는 저 수준(Low Level) 패키지 관리 도구인
'RPM(Redhat Package Manager)'의 경우패키지 종속성의 문제로 인해
내가 만약 "Game" 이라는 패키지를 설치하겠다고 하면,
"Game" 이라는패키지 하나만 설치하면 되는 것이 아닌
종속되어 있는 패키지들을 전부 설치해야 하는 것이다.
.. 이게 맞는 비유일지는 모르겠으나"책상"이라는 물체를 이루려면
"책상다리", "못", "받침대" 등이 서로 연결되어 책상을 이루는 것과 비슷하다.
이렇듯 우리가 하나의 패키지를 손수 설치하려면 그 과정이 짧을 수도 있겠지만
대부분의 패키지는 갖가지 다른 패키지(요소)들로 이루어져 매뉴얼로
설치하기는 굉장히 귀찮고 어려울 수도 있는 일이다.
이런 점을 보완해 원하는 패키지만 설치를 요청하면 그에 종속된 패키지까지
전부 설치를 도와주는 "YUM" 이라는 패키지 관리 툴이다.
▼ yum 명령어의 사용 방식으로는 아래 코드블럭을 참고하자
yum
# Yellow dog Update Modified
yum ~ install
# 패키지를 설치
yum ~ check-update
# 설치된 패키지 중에서 업데이트 가능한 패키지를 출력
yum update ~
# 패키지를 업데이트 해주는 명령어
# 전체 업데이트도 가능하나, yum update -x [package] 처럼
# 특정 패키지를 제외하고 나머지를 업데이트 하는 것도 가능
yum search ~
# Repository 에서 설치될 수 있는 가용한 패키지를 검색
yum list ~
# 패키지의 설치 여부 등을 학인할 때 사용
● YUM Repository
yum에 패키지 연결경로를 추가시킬 때 소스 패키지와 이와 관련된 패키지들을 모아놓은 곳을
"리포지터리(Repository)" 라고 칭한다, "저장소"의 의미를 가지고 있다.
몇 가지 대표적인 방법으로 리포지터리를 사용해서 필요한 패키지를 설치할 수 있다.
1. CentOS 설치 시 자동으로 생성되는 "BASE"와 같은 리포지터리를 사용
2. CentOS 설치 시 DVD 등을 리포지터리로 사용
3. "EPEL"이나 "REMI"와 같은 별도의 리포지터리 설치해서 사용
ls /run/media/centos/~
'CentOS-7-x86_64-DVD-2009' 이미지를 가상머신에 마운트 후
Packages 디렉토리 안의 내용을 확인해보면 약 4070개의 rpm 패키지가 있는 것을 확인할 수 있다.
setenforce 0
# SELinux의 보안 설정을 임시적으로 비활성화
getenforce
# 현재 SELinux의 상태를 출력
Permissive
# 해당 상태로 표시되면 비활성화 되었음을 확인할 수 있다.
** 여기서 한 가지 빼먹은 부분이 있었는데 현재 상태로는 아마 클라이언트 PC에서 패키지
다운로드를 시도하면Mirror Site를 찾을 수 없다 등의 오류가 발생할 수 있다.
'SELinux'의보안설정에 의한 차단같은데, 이 부분도SELinux의 정책을 변경하면
굳이 비활성화를 하지 않더라도 연결에 지장이 없을 것으로 예상된다.
현재는 정확한 매커니즘을 이해하지 못 하고 있으므로,
** 추후에 SELinux에 대해서 학습할 때 추가적인 방안을 포스팅
이제 내부 저장소 서버에서의 설정은 거의 끝났다.
▼클라이언트 머신(2)에 접속하여 실습을 마무리 해본다.
sudo yum install -y ftp
내부 저장소 연결을 위한 ftp 패키지를 설치
Local Repository 설정 전 "nmap" 패키지 설치를 통해 현재 설정된 경로를 확인
Local Repository 설정이 완료되기 전 yum 명령어를 통해 패키지 다운로드를 시도했을 때,
시스템 디폴트 설정인 "base" 리포지터리를 통해서 패키지를 다운하는 것을 확인해볼 수 있다.
서버와 반대로 "client.repo"라는 이름의 저장소 경로 파일을 생성
'baseurl'의 경우 서버의 입장인 머신(1) 에서는 "/var/vsftpd/pub/server"라는 경로에 설정되어 있지만,
클라이언트 입장의 머신(2)에서는머신(1)의 IP주소와연결될 디렉토리의 경로까지 설정을 해줘야한다.
** 'gpgcheck'란 외부에서 받아오는파일의 무결성을 인증해주는 키로 인증하는 것을 의미,
기본 값으로는 각종 패키지들을외부의 ftp 서버에서파일을 받아오는 형식이기에
인증을 활성화시켜줬지만,현재는 내부 저장소에서패키지를 받아올 것이기에
굳이활성화시키지 않은 것이다.
이건 편법이다. 원래 이렇게 하면 안된다.
리포지터리의 동작여부를 직관적으로 느낄 수 있도록 임의로 디폴트 리포지터리를
전부 옮기고 해당 디렉토리에 새로 생성하여 설정해 둔"client.repo"파일만 남겨 놓았다.
** 이 부분도 원래는 각각의리포지터리에 우선순위(Priority) 값을 줘서우선순위 지정이 가능함
sudo yum erase -y nmap
# remove가 아닌 erase로 종속파일 제외 앞에서 설치한 'nmap'만을 삭제
sudo yum clean all
# yum 캐시 데이터를 삭제(오류를 피하기 위함)
sudo yum repolist all
# Repository 목록을 출력
RAID(Redundant Array of Independent / Inexpensive Disks)
비휘발성 저장장치(HDD) 여러대를 병렬, 직렬형태로 연결하여 손실된 데이터의 복구를 가능하게끔 설계하는 구성 방식이다. RAID 구성 방식으로는 몇 가지 다양한 방식이 있지만, 주로 사용되는 방식은 RAID 0, RAID 1, RAID 5, RAID 1 + 0 방식이 있다.
● RAID 0 (Disk Striping)
자료출처 : https://commons.wikimedia.org
RAID 0 방식의 경우 데이터 복원은 되지 않지만, 디스크의 헤드와 암(arm)이 늘어나게 되는 것이니 데이터 처리의 속도가 빨라진다는 장점이 존재한다. 이렇게 하나의 데이터를 분산시켜 처리하는 Disk Striping이라고 한다.
● RAID 1 (Mirroring and Duplexing)
자료출처 : https://commons.wikimedia.org
데이터 복원이 가능한 방식의 RAID 구성으로, 두 개의 디스크를 사용한다고 했을 때 Disk 0에 데이터를 저장하게 되면 Disk 1 에도 동일한 데이터가 저장되어 백업이 되는 방식이다. 추가가 된 디스크에는 같은 용량의 정보가 저장되기 때문에 용량 증가의 효과는 없다. 주로 중/소 조직에서 사용되며, 이를 Mirroring 이라고 한다.
● RAID 5 (Stripe with Parity)
자료출처 : https://commons.wikimedia.org
데이터 복원이 가능한 RAID 구성으로, 세 개 이상의 디스크를 필요로 하며, Parity bit 를 사용해서 데이터를 복구할 수 있다는 특징이 있는 구성방식이다. Odd Parity(홀수), Even Parity(짝수)로 설정(Default == Odd Parity)할 수 있으며 비트를 계산하여 오류의 여부를 확인해서 복원 시켜주는 것(사진첨부)
Even Parity bit로 오류를 식별
● RAID 1 + 0 (Striping + Mirroring)
자료출처 : https://commons.wikimedia.org
RAID 1(Striping) 과 RAID 0(Miroring) 을 합친 구성방식으로 데이터의 신뢰성과 처리속도의 향상을 목적으로 사용된다.
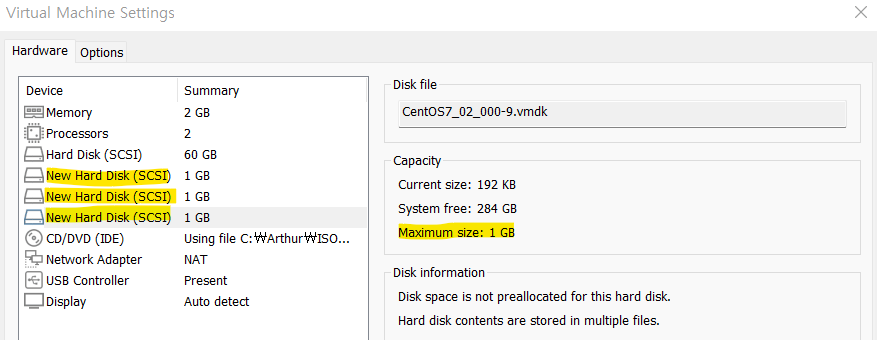
● RAID 5 실습
RAID 5를 구성할 하드디스크 3개를 추가
fdisk 명령어로 추가된 3개의 디스크를 "Linux raid auto" 형식으로 파티션 진행
파티션 후 바로 포맷이 아닌, 파티션된 디스크를 "mdadm" 명령어로 RAID로 묶어준 후 포맷을 진행
ext3 형식으로 파일 시스템 포맷을 진행
저장공간이 3GB가 아닌 2GB로 표시되는 것을 보아, RAID 5 구성이 되었음을 확인
마운트포인트에 RAID 구성이 된 하드디스크를 마운트
RAID 디스크 삭제 전 마운트 포인트에 파일을 생성(** 사진 우측하단 확인)
디스크 하나가 유실 되었음에도 저장된 파일이 손상되지 않음을 확인(** 사진 우측하단 확인)