Log Server(Rsyslog를 활용한 원격 로그서버)
OS의 종류를 막론하고 서버, 시스템을 관리하는 시선에서의 로그(Log)는 굉장히 중요한 파일이자 증거물이다.
로그는 커널, 보안관련, 서비스 등지에서 발생하는 이벤트에 대해 기록되는 것으로,
기본적으로 리눅스에서는 'rsyslog' 패키지의 데몬을 통해서
로컬(/var/log/~) 혹은 원격 로그 서버(Remote Log Serverr)에 저장하게 된다.
(FTP, DB, HTTP .. 등의 메인 서버에서 발생하는 로그의 관리방식)
로컬 머신에 저장되는 로그의 경우 해커가 작업을 마친 후 로그를 삭제하면
그 증거를 찾아내기 어려워지지만, 실시간으로 발생하는 로그를
원격지의 서버로 SSH를 통하여 전송하여 통합 저장 및 관리를 한다면
보다 안전하고 효율적으로 관리할 수 있을 것이다.
* 실습환경 : Intel i7-1260P(AMD64)
** 네트워크 대역 : 192.168.100.0/24
*** 해당 실습에서 사용된 가상 머신 : CentOS 1(LogServer .140), CentOS 2(Client, ditto.com, .160),
Ubunser(.135)
● Rsyslog를 활용한 원격 로그서버 구축
# CentOS7 1(.140 == Remote Log Server)
# rsyslog 패키지를 설치(대부분 기본 패키지로 설치 되어있음)
sudo yum install -y rsyslog
# 기본 설정파일 백업 생성
sudo cp -arp /etc/rsyslog.conf /etc/rsyslog.conf.bak
# rsyslog 서버의 /etc/rsyslog.conf 파일 내용 수정
[파일 내용]
14 # Provides UP syslog reception
15 $ModLoad imudp
16 $UDPServerRun 514
18 # Provides TCP syslog reception
19 $template TemlAuth, "/var/log/%HOSTNAME%/PROGRAMNAME%. log"
20 *.*?TemlAuth
21 $ModLoad imtcp
22 $InputTCPServerRun 514
# 원격 로그 서버로 사용될 머신에서 514포트(syslog Protocol) 부분의 주석을 해제
# 19번 째 라인을 보면 새로운 템플릿을 정의한 후 원격지(클라이언트)에서 수신받는 로그의 저장 경로를 지정
# 20번 째 라인의 경우 모든상황에 대한 모든 메시지를 수신한다는 의미
[파일수정 완료 후]
sudo firewall-cmd --permanent --zone=public --add-port=514/tcp
sudo firewall-cmd --permanent --zone=public --add-port=514/udp
sudo firewall-cmd --reload
sudo systemctl restart rsyslog && sudo systemctl status rsyslog
# 방화벽 설정 적용과 수정내용 적용을 위한 재시작을 실행


포트 개방 상태를 확인
▼ Centos7 2(.160, Client)

"*.info;mail.none;cron.none@192.168.100.140(원격 로그 서버의 IP주소)"
info 레벨의 로그를 전송하는데, mail과 cron에서 발생한 이벤트에 대해서는 전송하지 않는다는 의미를 가진다.

설정파일 적용을 위해 서비스를 재시작 후 상태를 확인한다.
▼ Ubunser(.135, SSH Client)

▼ 결과물(Report)


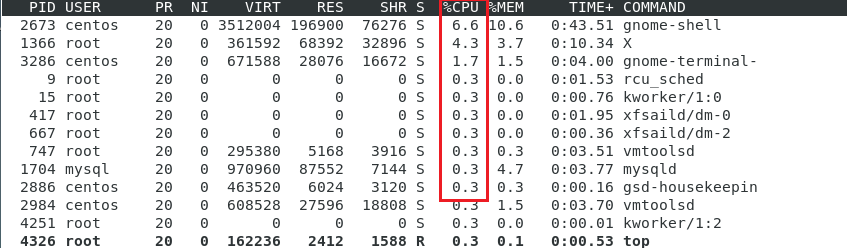
몇 분 차이로 클라이언트 머신에서는 다른 이벤트가 발생하여 내용이 추가되었지만,
서버의 SSHD 관련 로그와 내용을 비교 해보았을 때, 내용이 일치하는 것을 확인할 수 있다.
동기화가 정상적으로 이루어졌다는 의미
'Linux_System' 카테고리의 다른 글
| [Linux]DHCP (0) | 2023.02.10 |
|---|---|
| [Linux]Squid(Proxy_Server) (0) | 2023.02.09 |
| [Linux]Ansible (0) | 2023.02.04 |
| [Linux]YUM_Priority (0) | 2023.01.18 |
| [Linux]ZFS (0) | 2023.01.16 |